Training-Free Process Rewards for LLM RL
Published:
Motivation
Current RLVR (RL from Verifiable Rewards) frameworks typically assign a single reward at the end of a response—correct or incorrect. But not all reasoning steps contribute equally. Some are critical insights, others are routine algebra, and some may be wasteful exploration.
Process rewards assign credit to intermediate steps, enabling step-level credit assignment. This unlocks several applications:
- Better training efficiency: Denser reward signal provides more gradient information per sample
- Breaking out of zero pass rate: When a problem is too hard for any complete solution, partial progress can still be rewarded
- Less verbosity: Penalize unproductive reasoning loops and overthinking
The Challenge
How do you obtain step-level reward signals? Two main approaches:
- Train a Process Reward Model (PRM): Requires labeled data for intermediate steps [1] or a strong model judge
- Training-free signals: Derive rewards from the policy itself
Note that if you have a well-trained value network, that naturally provides token-level process rewards via TD-error. Value network training is out of scope for this post—we focus on training-free approaches that work with critic-free algorithms like RLOO/GRPO.
Training-Free Process Rewards
Monte Carlo Estimation
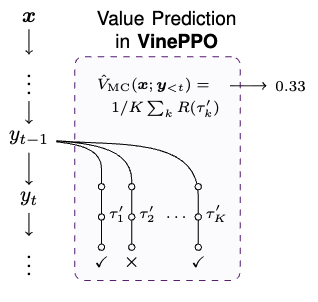
A key insight from VinePPO [2]: language environments are naturally “resettable”—you can return to any intermediate state simply by prompting with that prefix. This enables estimating V(prefix) at any point in a reasoning trace.
VinePPO uses Monte Carlo estimation: sample K complete rollouts from each prefix and average their outcomes. This is expensive—for N steps and K samples, you need N×K rollouts per training example.
Log-Probability Approximation
We approximate V(prefix) more efficiently using a single forward pass. The idea: instead of sampling K completions and checking correctness, compute the model’s log-probability of the known correct answer when forced to answer immediately. This avoids the cost of sampling completions while correlating with the true V(prefix).
\[V(\text{prefix}) \approx \frac{1}{n}\sum_{i=1}^{n} \log P(a_i \mid \text{prefix} + \text{force\_prompt} + a_{<i})\]Concretely, we:
- Truncate the response at an episode boundary
- Append a “force answer” prompt (e.g.,
</think>\n\nThe answer is) - Compute the mean log-probability of the ground-truth answer tokens
We use log-probability directly (not converted to probability) for numerical stability. This estimates “if the model were forced to answer now, how likely would it produce the correct answer?”
Assumptions and limitations:
- A small set of correct answers (e.g., math problems with a single numerical answer). If the space of correct answers is large (e.g., open-ended instruction following), this approach won’t work.
- A compatible force-answer prompt. The prompt (e.g.,
</think>\n\nThe answer is) must be consistent with the model’s chat template and training format. - Biased estimate. Unlike Monte Carlo, this does not provide an unbiased estimate of V(prefix). We are effectively using the base model with a force-answer prompt as a prover policy [4][5]—a separate policy that completes the solution from an intermediate state. The quality of V(prefix) depends on how well this prover correlates with the true probability of success.
Episode Segmentation
To identify intermediate states, we segment reasoning traces into “episodes” using discourse markers:
EPISODE_MARKERS = [
"Wait,", "Alternatively,", "Actually,", "Hmm,",
"Let me ", "I need to ", "So ", "But ",
# ... more markers
]
Each marker indicates a potential state boundary where we can evaluate V(prefix).
We also use a token length fallback: if no markers are found within a maximum token limit (e.g., 256 tokens), we split at sentence boundaries. This prevents issues where the model produces no markers at all, which would result in a single giant episode.
flowchart LR
A[Full Response] --> B[Segment by markers]
B --> C[Episode 1: Problem setup]
B --> D[Episode 2: Initial approach]
B --> E[Episode 3: Wait, let me reconsider...]
B --> F[Episode N: Final answer]
C --> G["V(prefix₀)"]
D --> H["V(prefix₁)"]
E --> I["V(prefix₂)"]
F --> J[Final reward]
Marginal Utility
With V(prefix) at each episode boundary, we compute marginal utility:
\[U_i = V(\text{prefix}_i) - V(\text{prefix}_{i-1})\]Since V(prefix) is in log-probability space, the difference measures the log-odds improvement from each episode.
U_i > 0: Episode i made progressU_i < 0: Episode i was counterproductiveU_i ≈ 0: Episode i didn’t change much (possibly wasteful)
Common Implementation Pitfalls
Computing process rewards is the easy part. The harder part is getting them through the training pipeline without silently destroying the signal. There are two ways your pipeline can silently eat the process reward signal — one destroys the spatial structure (which tokens get credit), the other destroys the scale (how much credit). Both result in training that runs without errors but learns nothing from the process rewards. We discovered them in VeRL, but they stem from how GRPO-style algorithms are typically implemented, not from any framework-specific bug.
Pitfall 1: Advantage Estimators Destroy Token-Level Structure
Most GRPO implementations immediately collapse token-level rewards to scalars:
# What most GRPO implementations do:
scores = token_level_rewards.sum(dim=-1) # [batch, seq_len] → [batch]
advantages = (scores - group_mean) / group_std # scalar per sequence
This destroys the fine-grained credit assignment you carefully designed. Your process rewards—which vary across episodes within a sequence—are summed into a single number before computing advantages. Every token in the sequence receives the same advantage, regardless of whether its episode was productive or counterproductive.
The critical question for your framework: Does your advantage estimator use token_level_rewards[:, t] at each timestep, or does it sum first? If it sums first, you need a token-level preserving estimator.
Fix option 1: Use GAE. The GAE (Generalized Advantage Estimation) estimator naturally preserves token-level structure:
for t in reversed(range(seq_len)):
delta = token_level_rewards[:, t] + gamma * nextvalues - values[:, t]
lastgaelam = delta + gamma * lam * lastgaelam
Fix option 2: Token-preserving GRPO. If you want to stay within GRPO, implement a variant that normalizes per-token rewards by group statistics, then computes advantages as cumulative sums (return-to-go). The cumsum is important: a token’s advantage should reflect all future reward from that point onward, not just its own episode’s marginal utility — otherwise early tokens that set up a productive reasoning chain get no credit for the payoff.
# Collect all rewards from group
group_rewards = torch.cat([rewards[i, mask[i]] for i in group])
# Normalize each token by group statistics
mean_R = group_rewards.mean()
std_R = group_rewards.std()
rewards_normalized = (rewards - mean_R) / std_R
# Compute advantages as return-to-go (cumulative future reward)
advantages = rewards_normalized.flip(-1).cumsum(-1).flip(-1)
Pitfall 2: Mixed Reward Scales
When combining outcome rewards with process rewards, normalize them separately.
Outcome rewards (0/1 binary correctness) and process rewards (marginal utility, typically ~±0.03) differ by 1–2 orders of magnitude. If you normalize the combined reward tensor, the process reward signal becomes negligible—outcome rewards dominate the statistics.
Fix: Identify and normalize each reward type separately before combining:
# Outcome rewards at last token (like standard GRPO)
outcome_mask = ... # last valid token of each response
id2outcome[group_idx].append(token_level_rewards[i][outcome_mask[i]])
# Process rewards at episode boundaries (separate normalization)
process_mask = nonzero_mask & ~outcome_mask
id2process[group_idx].append(token_level_rewards[i][process_mask[i]])
Optimization: Pre-compute During Generation
Computing V(prefix) requires forward passes through the policy model. If done during the reward computation phase, this blocks the training loop.
The fix is general: pre-compute V(prefix) during the generation phase, when the actor model is already loaded for rollout. Store the results and retrieve them cheaply during training.
# During generation phase (actor already loaded):
# 1. Generate response
# 2. Segment into episodes
# 3. For each episode boundary:
# - Construct prefix + force_answer_prompt + ground_truth
# - Compute log_probs using actor (already loaded!)
# - Store V(prefix) in cache
# During training phase:
# 1. Retrieve pre-computed V(prefix) from cache
# 2. Compute marginal utilities (cheap math)
# 3. Compute process rewards (cheap math)
This gave us 60-70% speedup compared to computing everything during the training phase.
VeRL Implementation Notes
The pitfalls above apply to any framework. This section covers VeRL-specific details for anyone implementing process rewards there.
Reward Manager Architecture
VeRL provides two architectures for reward computation:
Legacy RewardManager (Synchronous):
class StepProgressRewardManager:
def __call__(self, data: DataProto) -> torch.Tensor:
# Compute rewards synchronously
return reward_tensor # [batch_size, seq_len]
- Has access to the actor model
- Blocks the training loop during computation
- Simple to implement and debug
Important: To use a custom RewardManager, you must set use_reward_loop=False in your config. Otherwise, VeRL defaults to the RewardLoopManager and silently bypasses your custom reward manager—a subtle source of bugs.
RewardLoopManager (Async) — Now Default:
class CustomRewardLoopManager:
def __init__(self, reward_model, ...):
self.reward_model = reward_model # Separate model instance (e.g., vLLM)
async def compute_rewards(self, data):
# Async reward computation
return reward_tensor
- Async processing—doesn’t block training
- Well-suited for external reward models (trained RMs, LLM-as-judge, rule-based verifiers)
- Does not have access to the actor model’s current weights
| Use Case | Recommended |
|---|---|
| External RM (trained reward model) | RewardLoopManager |
| LLM-as-judge | RewardLoopManager |
| Rule-based verification | Either works |
| Rewards derived from actor model (e.g., V(prefix)) | Legacy RewardManager |
Key consideration: If your reward computation requires the current policy (e.g., estimating V(prefix) for process rewards), the RewardLoopManager creates synchronization issues—the reward model copy can diverge from the actor during training. In this case, the legacy RewardManager is more appropriate.
VeRL Data Flow
Here’s how rewards flow through VeRL’s training pipeline—and where token-level structure gets lost if you use the default GRPO path:
flowchart TD
A[RewardManager returns reward_tensor]
B[compute_reward in trainer/ppo/reward.py]
C[Store as token_level_scores]
D[apply_kl_penalty optional]
E[Store as token_level_rewards]
F[compute_advantage in trainer/ppo/core_algos.py]
G[GAE: Uses per-token rewards]
H[GRPO: Sums to scalar]
I[Token-level advantages]
J[Scalar advantages]
A --> B
B --> C
C --> D
D --> E
E --> F
F --> G
F --> H
G --> I
H --> J
classDef good fill:#d4edda,stroke:#28a745,stroke-width:2px
classDef bad fill:#f8d7da,stroke:#dc3545,stroke-width:2px
class G good
class H bad
The GRPO path (red) sums to scalar at core_algos.py:301—this is where Pitfall 1 hits. The GAE path (green) preserves token-level structure. If you implement process rewards in VeRL, make sure you’re on the GAE path or have implemented a token-preserving GRPO variant.
Adding Process Rewards to Your Pipeline
If you’re integrating process rewards into an existing RL setup, check these three things in order — each is a prerequisite for the next to matter:
Does your advantage estimator preserve token-level structure? Run a batch with process rewards and inspect the advantage tensor. If every token in a sequence has the same advantage value, your estimator is collapsing to scalars. Switch to GAE or a token-preserving GRPO variant before proceeding — nothing else matters until this works.
Are your reward scales separated? Log the mean and std of your advantage tensor with and without process rewards enabled. If the statistics barely change, the process reward signal is being drowned out by outcome rewards. Normalize each reward type independently.
Can you pre-compute during generation? V(prefix) requires a forward pass through the policy. If you’re computing it during the training phase, you’re adding 60-70% overhead. Move it to the generation phase where the actor is already loaded.
References
[1] Lightman, Hunter, et al. “Let’s verify step by step.” The Twelfth International Conference on Learning Representations. 2023. https://arxiv.org/pdf/2305.20050
[2] Kazemnejad et al. (2024). VinePPO: Unlocking RL Potential For LLM Reasoning Through Refined Credit Assignment. https://arxiv.org/abs/2410.01679
[3] VeRL: Volcano Engine Reinforcement Learning for LLMs. https://github.com/volcengine/verl
[4] Setlur et al. (2024). Rewarding Progress: Scaling Automated Process Verifiers for LLM Reasoning. https://arxiv.org/abs/2410.08146
[5] Qu et al. (2025). Optimizing Test-Time Compute via Meta Reinforcement Fine-Tuning. https://arxiv.org/abs/2503.07572